
Workshop hosted by the Centre of Interdisciplinary Methodologies (CIM), University of Warwick.
Co-organised with the Public Data Lab.
The Digital Test of the News workshop brought together digital sociologists, data visualisation and new media researchers at the Centre for Interdisciplinary Methodologies at the University of Warwick on 8 and 9 May 2018. The workshop is part of a broader research collaboration between the Centre for Interdisciplinary Methodologies and the Public Data Lab which investigates the changing nature of public knowledge formation in digital societies and develops inventive methods to capture and visualise knowledge dynamics online. Below we outline the workshop’s aims and outcomes.
With the participation of: Federica Bardelli (Politecnico di Milano), Andreas Birkbak (University of Aalborg), Liliana Bounegru (Oxford Internet Institute), Jonathan Gray (King’s College London), Noortje Marres (University of Warwick), Greg McInerney (University of Warwick), David Moats (Linkoping University), James Tripp (University of Warwick) and Esther Weltevrede (University of Amsterdam).

The workshop (Photo: Jonathan Gray).
The Digital Test of the News project finds its starting point in growing concerns that have emerged over the past years about the role of online media platforms in opinion manipulation, mistrust in experts and journalists, and the degradation of public knowledge cultures. These concerns have led to significant investments in fact-checking and verification technologies and services that seek to evaluate the veracity of statements circulating online and the credibility of their sources (Smyrnaios, Chauvet & Marty, 2017). While such approaches are proving useful (Full Fact, 2018), it is widely acknowledged that existing fact-checking methodologies suffer from limitations: in particular, current approaches are not well equipped to assess emergent statements in fast-moving and contested areas of public knowledge formation. As a consequence, they may overlook important transformations in public knowledge-making in digital societies. Attending to these transformations may enable innovation in fact-checking methodologies, and more broadly help to develop research, advocacy and policy agendas to evaluate and inform public knowledge formation in digital societies.
What fact-checking does
Fact-checking initiatives like Full Fact and Snopes intervene in public discourse not just by validating statements but also by informing wider understandings of how to draw the boundary between legitimate and illegitimate contributions to public knowledge.
Fact-checking initiatives use a variety of methods for the evaluation of empirical claims (Graves & Cherubini, 2016; Graves, 2018). One prominent method is to cross-reference empirical claims against accredited or credible sources. This may be done following established editorial practices – which have been dubbed “human moderation” – or with the aid of automated content analysis, with the latter matching individual statements against an archive of verified statements. The latter approach, in particular, can be said to reinstate a demarcationist approach to public knowledge: it draws a boundary between valid and invalid statements, and treats truth and falsity as fixed attributes of individual statements. Instruments like the prototype Factmata platform check online statements against a database of validated propositions, and on this basis label a statement as true or false, bringing it in line with well-established philosophical traditions like the positivist verification methodology which proposes to validate scientific discourse by way of a procedure for tracing knowledge claims back to so-called verifiable observational statements (Marres, 2018). It also reminds us of the “Test of the News” conducted in the 1920s by the American journalist Walter Lippmann. In his test Lippmann compared news reports to witness statements with respect to a historic event – the Bolshevik revolution – in order to judge the reliability of news through comparison with observational reports by sources “on the ground” (Steel, 1999).
By activating the concern for truth and reliability, these methodologies have the potential to re-invigorate public knowledge culture, and they have been effective in exposing damaging attempts to manipulate public opinion. But they also suffer from limitations. While existing fact verification initiatives are well equipped to address misleading statements about established facts (such as what UK’s GDP in 2016 was), news reporting and public knowledge rarely deal only with such established knowledge claims. Most often news and the public domain are confronted with complex propositions, the elements of which operate in different registers of knowledge and opinion, from the descriptive to the speculative, and occupy different stages of formulation, re-formulation and stabilisation, and accordingly, each have a different validity status. As claims undergo re-formulation in public media, the truth value of these propositions is also likely to fluctuate. This is true in the case of scientific statements, where the achievement of consensus on truth value and validity conditions can be especially fierce, and is also evident in public discourse. Here empirical claims – say about the reported relation between immigration and the price of housing (BBC, 2018) – may be taken up and re-formulated by many different actors, with their truth value fluctuating in the process. When Dominic Raab claimed that immigration had pushed up house prices by 20%, it subsequently became clear the claim was based on a model from 2007, when the government released the data behind the claim (Ministry of Housing, Communities and Local Government, 2018). This significantly qualified the claim, as it turned out to pertain to a previous period and not the current moment. We use the notion of experimental fact (Marres, 2018) to draw attention to these claims that are unstable and undergo re-formulation over the course of the news or issue cycle. Precisely because of their dynamism, such experimental facts have the capacity to organise public debates, but the flipside of this is that their epistemic status and “aboutness” – the question of what the object of the claim is, what it refers to – is not settled.
From the standpoint of fact-checking, the evaluation of this type of public knowledge claim is very challenging because its validity is not easily determined by taking recourse to an established knowledge base: it is often precisely the element that is not easily verifiable and contested among experts, that secures the public relevance of these type of claims. Moreover, the evaluation of their worth or validity is likely to impact their circulation and uptake. Attempts to flag fraudulent claims may also backfire, as the labelling of a source as “unreliable” may risk seeming patronising or naive. Labelling a statement as false may also become a strategic weapon in the hands of opponents and thus may further polarise political environments. The assumption that the job of fact checking is to establish the truth value of public knowledge claims, may then put us at risk of mis-communicating how public discourse operates, and, more generally, foreclose possibilities to endorse or imagine meaningful and generative contributions of public participation to knowledge formation and validation.
Testing public knowledge beyond verification: The [350 million + NHS + Bus] claim
Taking this broad problematic as our starting point, the Digital Test of the News workshop set out to put the notion of experimental facts to the test by exploring how we could empirically detect its features: what makes a claim a statement of experimental fact? What methods can we use to detect these features in online discourse? To address these questions, we selected a candidate “experimental fact” and developed a digital analytic procedure to discover and document fluctuations in its truth value over time.
It should be noted that there have already been several attempts to develop data analytics in this direction, perhaps most notably in work on rumour detection (Procter, Vis, & Voss, 2013) and bias detection (Kulshresta et al, 2017; see also Marres, and Weltevrede, 2013). However, insofar as these methods tend to presume well-established truth conditions by which statements can be retrospectively (de-)validated, they do not fully engage with the limitations of correspondence-based methods: they are not designed to evaluate emergent claims in real-time.

Vote Leave referendum campaign tour bus with the ‘350 Million to the NHS’ slogan
To test our prototype protocol for the detection of an experimental fact on the Web, we decided to focus on the (in)famous statement that Brexit will make available 350 million pounds per week for the NHS. This seemed a good test candidate because the “350 Million to the NHS” claim was first criticized and debunked but then reformulated by various actors participating in public discourse in the UK. The statement began its life as one of the main slogans of Vote Leave’s referendum campaign, as it was plastered on the big red bus that the campaign used to tour the country in white letters: “We send the EU £350 million a week – let’s fund our NHS instead – Vote Leave – Let’s take back control.” Since then, [350 million+NHS+bus] became a deserving target of fact-checking efforts and interventions by respected authorities like the Office for National Statistics as well as dedicated fact-checking organisations, like Full Fact. Interestingly, however, the claim was subsequently taken up and reformulated by a range of different actors in the following months, and indeed years, in ways that directly addressed – and affected – its validity and truth value. As The Spectator put it in May 2018, two years after the claim first appeared on the faithful bus, “£350 million for the NHS: How the Brexit bus pledge is coming true”. As Marres (2018) notes elsewhere:
“When [the] statement was first plastered onto a red bus during the referendum campaign, it qualified as a robust example of ‘post-truth politics’. According to the UK Office of Statistics, the claim presented a ‘clear misuse of statistics’. However, in later speeches, debates, and analysis, it came to signal something else as well: it highlighted the role of cuts and austerity in swinging the Brexit vote. The statement, as time passed, remained highly problematic but subsequent operations upon it arguably made it less un-true. As Simon Stevens, Head of NHS England stated: The health service ‘wasn’t on the ballot paper, but it was on the battle bus’. The popularity of the Brexit bus, that is, came to serve as evidence for the widespread public concern with the state of the NHS. The rise to prominence of the 350 million NHS claim, then, is then not just indicative of the influence and danger of attempts at public opinion manipulation in political campaigning. [The] public interest in this claim that materialized as a bus on the country’s roads was subsequently recognized as a valid attempt at issue articulation: something must change in this country so that public investment can return to vital services across regions.”
There are thus a number of reasons why [350 million+bus+NHS] may be qualified as an experimental fact. The proposition circulated with frequency and endurance among an extensive set media of sources of diverging orientations in the UK. There is a public knowledge base, as a range of experts, advocates and commentators have taken public position on the veracity, validity and plausibility of this claim. It seems possible, at least in principle, to posit binary truth conditions for the claim (it has facticity). A further notable feature of the claim is the instability of what the statement is about: Is it about the EU? Is it about the underfunding of the NHS? Is it about austerity?. The possibility of conclusively resolving this question resides in the future. Finally, it should be noted that the question of the referent of this statement does not fully sum up its public relevance: opposing factions attached additional issues to the claim, which may be expected to continue to undergo modification along the trajectories of its mediatization (Moats, 2018).
However, while we may be able to give a theoretical definition of an experimental fact, and sketch out how it is applicable to [350 million+bus+NHS], the question remains: how do we operationalize these features so as to discover and respond to them in online discourse? During our two-day workshop at Warwick we therefore set ourselves the admittingly challenging task of determining by way of data analysis whether and how [350 million + NHS + Bus] qualifies as an experimental fact. We did this by empirically analysing fluctuations in the composition of the claim (“key phrases”) over time, which would then provide a basis for interpreting possible shifts in the claim’s truth value.
Towards a protocol for testing experimental facts
To test whether [350 million + NHS + Bus] qualifies as an experimental fact, our first step was to curate a dataset that would capture some of the circulation of this claim in public media online and that would enable us to identify prominent re-formulations over time (on this point see also Rogers & Marres, 2000). To build such a corpus of public reports and media articles associated with the statement, we queried Google Web search for [“350 million” OR “350m” AND “bus”] at six month intervals from the unofficial start of the referendum campaign, 20 February 2016 until 30 February 2018. We produced a timeline consisting of 5 intervals and collected 100 URLs per interval in this manner. To produce our dataset, we ran the resulting 500 URLs through Citron, a quote extraction and attribution system developed by the BBC IRFS (http://citron.virt.ch.bbc.co.uk/). In the spirit of digital methods research (Rogers, 2013), we then settled on a basic ontology for our experimental fact-check which is well aligned with the data structure that Citron outputs, namely that of key phrases associated with actors. We set it as our aim to identify: which key phrases and which actor types are most prominently associated with the [350 million + NHS + Bus] claim in each interval?
This research question was informed by previous work on bias detection and in particular on polarization in search and Twitter data (Borra & Weber, 2012). That work focused on the detection of types of actors associated with a key phrase to identify the degree of bias, ie the leaning of that term in online discourse. However, our test modifies this method in two crucial ways. First, our aim is not to establish the political colour of key phrases at a given point in time, but the extent to which they modify the truth value of the statement in question. Thus, adding “clear misuse of statistics” to the discourse, counts as a challenge to the validity of the statement – as it critiques accuracy. By contrast, phrases pertaining to the NHS – for example, “spend on priorities, like the NHS” – attempt to modify validity conditions in the opposite direction, by foregrounding the substantive point of reference of the claim, namely public investment needs. The identification of prominent modifiers of validity (truth value) in the discourse associated with the claim was thus our objective. It is also clear to us, incidentally, that such work requires interpretation and judgement by researchers – more about which below.
In focusing on identifying modifiers we follow Moats and Borra (2018) who analysed re-tweet chains to detect precisely the degree of modification as a measure of engagement, or even public-ness of a given statement. This also means that our objective in identifying which types of actors are associated with these claims is different from Weber and Borra’s. For us, determining which type of actors are prominently associated with a key phase does not serve to determine the political colour of that phrase, but to characterize its robustness and/or public status. If a relatively homogenous but partial set of actors out of a wider heterogenous actor pool is associated a claim (say Labour and Remain), this signals polarity in the debate, while a heterogeneous set of actor associations would signal contestation and/or instability of the claim’s status. We expect experimental facts to either display shifts in the polarity of key phrases and/or significant heterogeneity of actors.
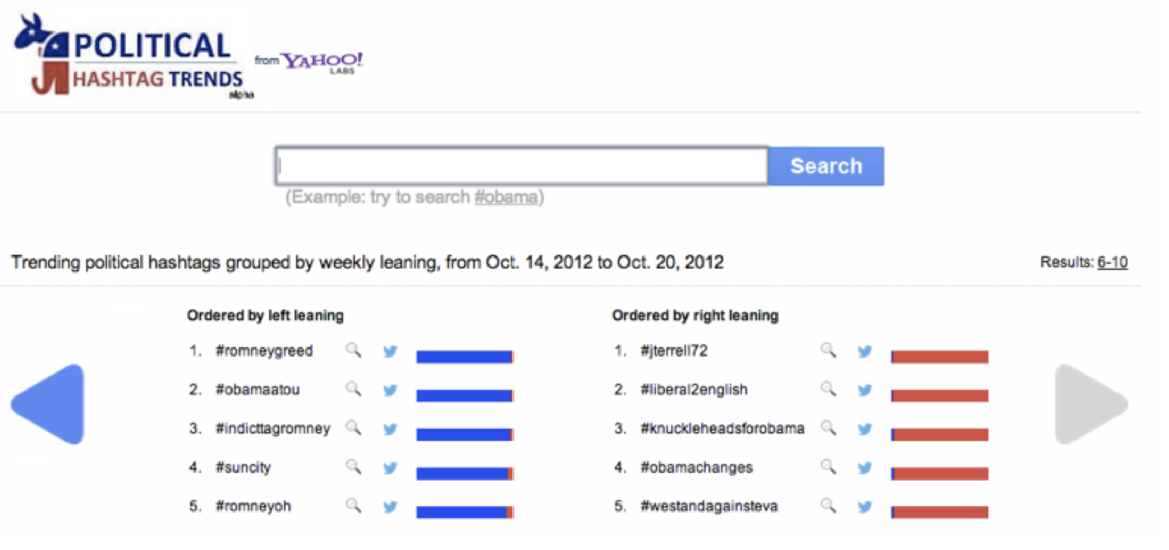
Screenshot of Political Insights. Top results for searches containing [obama]. Reproduced from Borra & Weber (2012).
Having extracted actors and statements from the URL collection per interval with Citron, we then settled on a lexicon-based method as a way to identify epistemic value modifiers in our corpus. Such methods are increasingly used in computational social science (Cointet & Parasie, 2018; Pushman, 2018) to measure the frequency with which words and phrases occur in a given corpus of text. Most recently it has been used by Carolin Gerlitz and Fernando van der Vlist (forthcoming) to mark up a large corpus of Youtube metadata.
Following Gerlitz and Van der Vlist, the lexicon we built during the workshop is corpus-specific. It consists of three levels: 1) type of entity (in our case, actors and phrases); 2) type of phrase or actor (eg actors: remainers, journalists,Tory politicians; eg phrases: public services, economy, etc.); 3) index words (words and phrases extracted from the text of the articles that indicate the presence of a category in our corpus of texts, eg “Theresa May”, “clear misuse of statistics”, etc.).
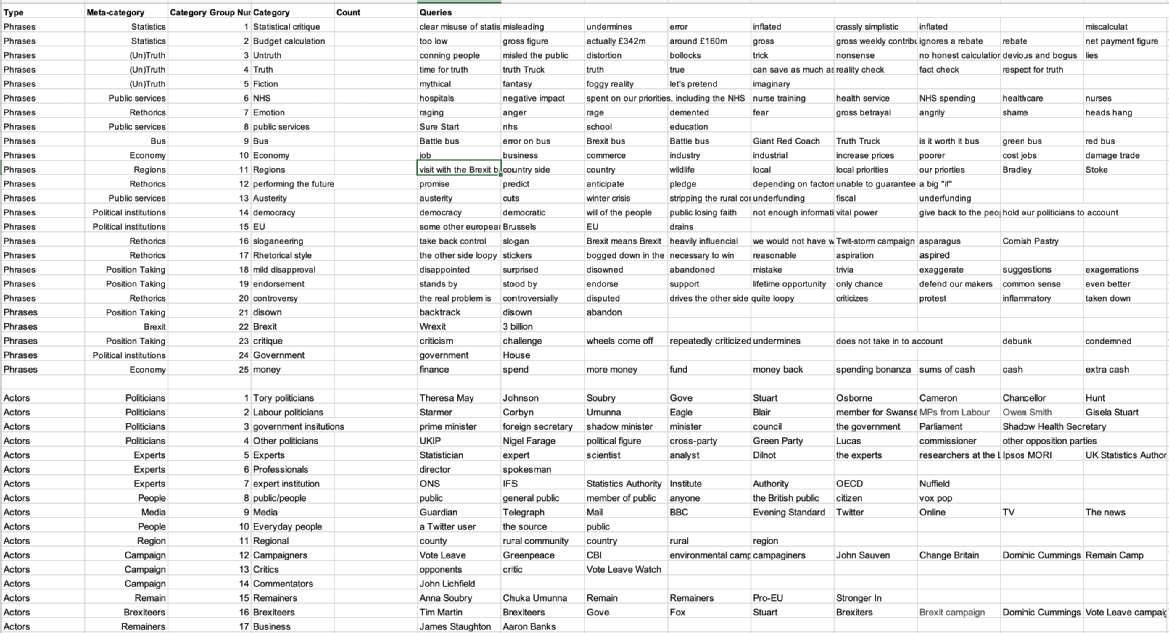
Screenshot from the lexicon developed during the workshop.
A key contribution of interpretative analysis in the implementation of such a computational method is to integrate it with the case study method. We do this by populating the lexicon with a data ontology that is attuned to the unique characteristics of the research question and corpus in question. In our case, the particular aim of lexicon construction was to help us identify key actors and key phrases in the data that could indicate epistemic shifts in the validity of our claim over time. The notion of epistemic modifier being a delicate and fragile one, we dedicated a considerable amount of workshop time to the construction of this lexicon of modifiers. We divided up the intervals among workshop participants, asking each participants to conduct close reading of a sample of the materials in our corpus in order to identify actors and phrases which they expected to make a significant difference to the statement’s truth value and/or validity and to its actor composition. An extensive group discussion of each proposed phrase and actor resulted in a final list of modifiers. During this time, academic technologist James Tripp tweaked the script that is now the prototype tool LE_CAT, for Lexicon-based Categorization and Analysis Tool. This tool allowed us to run the custom-made lexicon on the entire Citron parsed corpus and to identify occurrences and co-occurrences of phrases and actors in the Web sources that make up the corpus. At the same time the visualisation team explored ways in which the features of an experimental fact and its epistemic modifiers could be could be visually explored and communicated and started testing some of these approaches. We discuss some of these results in the next section.
Preliminary findings
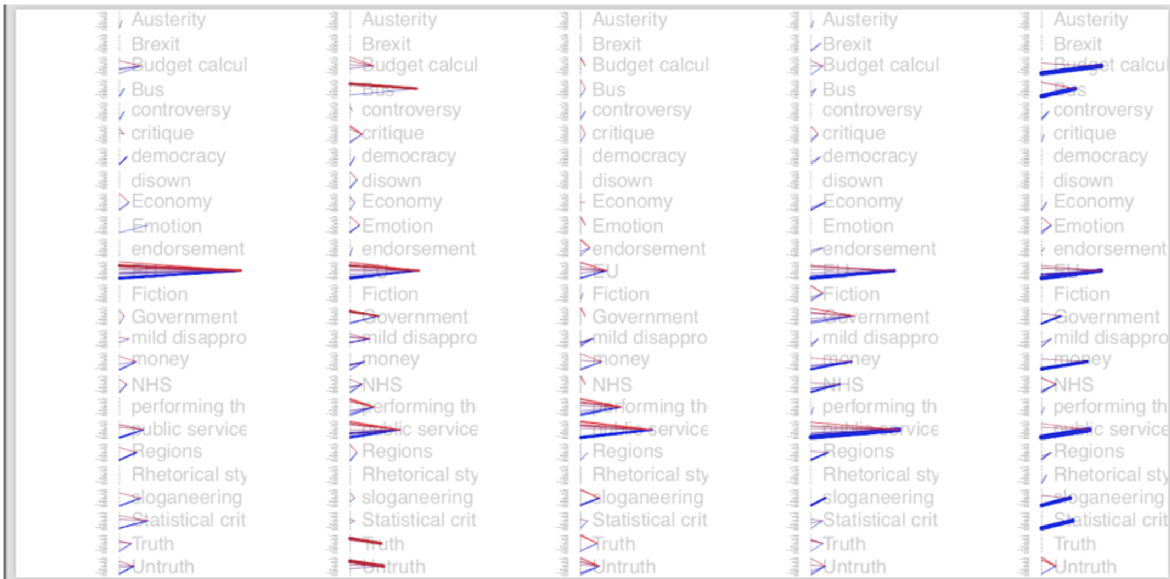
Visualisation sketch of actor types associated with key phrases in our corpus, with frequency of mention, based on an actor list ordering actor type from top to bottom, starting on top with remainers, Labour politicians, critics, campaigners, professionals, media, experts, public/people, business, expert institutions, other politicians, regional, governmental institutions, Tory politicians and Brexiteers. Sketch by G. McInerney
Running the purpose-built lexicon script on our data produced some preliminary findings as well as several further questions. First, mentions of truth and untruth seem to be decreasing over time: phrases associated with sloganeering, statistical critique, truth, untruth, budget calculation are prominent in interval 1 and 2, but they subside in intervals 3 and 4, which could be taken as a indication that challenges to the validity of the statement decreased over time. While in interval 1 and 2 preoccupation with the EU is strong, this is overtaken by a growing frequency of references to public services in interval 3 (although not so much the NHS!). This suggests a new possibility to us: that the very object (referent) of the [350 million+bus] claim may have changed over the course of time: while the so-called “bus pledge” started out as a statement about the EU – and one that had little to no validity as such – it became more closely associated with public services, and its perceived funding needs over time. This possible substitution of the primary object of reference of the claim may then lie behind the shift in truth value and the modification of its validity conditions.
As regards the actors, the visualisation shows for each term which actor type is associated with the term in question. Overall, we note a shift in the prominence of terms with a mostly progressive actor profile (like “EU”) to terms with a mostly conservative actor profile (which in this case includes the NHS!). The heterogeneity of actors associated with each of the different phrases seems to have decreased over time, with a gradual turn towards blue.
Next steps
These preliminary findings require further refinement and interpretation. In particular, we need to evaluate the lexicon, and its coverage of the corpus, both per interval and overall. As to our analysis, we note the following outstanding questions. First, regarding the notion of experimental fact, we wonder whether facticity itself could possibly be treated as a continuum: could the demise of the epistemic register – the use of truth terms like ‘gross misuse of statistics’; lies – be taken to indicate that the claim is losing its status an experimental fact? That is, should we consider it an empirical feature of public discourse, whether and how the question of truth value and epistemic validity moving into the background or foreground? Should we adjust our method to measure the degree to which facticity is at stake in a given issue area, in relation to a given claim?
Secondly, the team discussed to what degree a focus on truth modifiers needs to be complemented, or even, re-considered. The idea that the bus pledge has multiple referents – EU and public service, suggested another possible approach: should we focus on instability of the object or referent of a public claim, rather than its truth value? The aim of our analysis of facticity would then be to determine the extent of contestation over reference, and the wider capacity of public discourse to organise and or identify a robust object for a given claim.
As a last point, we identify as a priority the need to compare our approach – which we may dub “compositional analysis” (Clarke, 2003; see also Latour, 2010) – to related approaches, such as for example frame analysis, which is more customarily pursued when social scientists take up lexicon-based methods (Pushman, 2018). A compositional analysis is focused on determining what entities are put together in the collective effort to make an action-able object emerge (see, Goodwin, 1994 on this endeavour of letting the object emerge). Such an approach, we feel, has the significant advantage of affirming that facticity is at stake in public discourse. The idea that frames organise meaning, does not generally touch upon the question of reference, and this is indeed one reason why fact-checking is so important: it re-activates the question of reference in public discourse as a key social, political and moral concern. However, our definition of experimental fact – multiple objects, unstable truth values – needs to be further operationalized if we are to specify implementable ways to extend and modify fact-checking methodology and make it applicable to this type of claim.
References
Benkler, Y., Roberts, H., Faris, R. M., Etling, B., Zuckerman, E., & Bourassa, N. (2017). Partisanship, Propaganda, and Disinformation: Online Media and the 2016 U.S. Presidential Election. Retrieved from https://dash.harvard.edu/handle/1/33759251
Borra, E., & Weber, I. (2012). Political Insights: Exploring partisanship in Web search queries. First Monday, 17(7). https://doi.org/10.5210/fm.v17i7.4070
Clarke, A. E. (2003). Situational Analyses: Grounded Theory Mapping After the Postmodern Turn. Symbolic Interaction, 26(4), 553–576. https://doi.org/10.1525/si.2003.26.4.553
Cointet, J.-P., & Parasie, S. (2018). Ce que le big data fait à l’analyse sociologique des textes. Revue française de sociologie, Vol. 59(3), 533–557. Retrieved from https://www.cairn.info/revue-francaise-de-sociologie-2018-3-page-533.htm?contenu=article
Forsyth, J., & Nelson, F. (2018, May 8). £350 million for the NHS: How the Brexit bus pledge is coming true | The Spectator. Retrieved from https://www.spectator.co.uk/2018/05/350-million-for-the-nhs-how-the-brexit-bus-pledge-is-coming-true/
Full Fact (2018) Tackling misinformation in an open society, a Full Fact Paper, October, https://fullfact.org/media/uploads/full_fact_tackling_misinformation_in_an_open_society.pdf
Gerlitz, C and F. van der Vlist, Correlating Genre and Feature in the App Economy, Media of Cooperation working paper series, University of Siegen, forthcoming.
Goodwin, C. (1994). Professional Vision. American Anthropologist, 96(3), 606–633. Retrieved from https://www.jstor.org/stable/682303
Graves, L. (2018). Understanding the Promise and Limits of Automated Fact-Checking (p. 8). Reuters Institute for the Study of Journalism.
Graves, L., & Cherubini, F. (2016). The Rise of Fact-Checking Sites in Europe (p. 40). Reuters Institute for the Study of Journalism.
Kulshrestha, J., Eslami, M., Messias, J., Zafar, M. B., Ghosh, S., Gummadi, K. P., & Karahalios, K. (2017, February). Quantifying search bias: Investigating sources of bias for political searches in social media. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing (pp. 417-432). ACM
Latour, B. (n.d.). An Attempt at a “Compositionist Manifesto.” New Literary History, 20.
Marres, N. (2018). Why We Can’t Have Our Facts Back. Engaging Science, Technology, and Society, 4(0), 423–443. Retrieved from https://estsjournal.org/index.php/ests/article/view/188
Marres, N., & Weltevrede, E. (2013). SCRAPING THE SOCIAL?: Issues in live social research. Journal of Cultural Economy, 6(3), 313–335. https://doi.org/10.1080/17530350.2013.772070
Moats, D. (2017). From media technologies to mediated events: a different settlement between media studies and science and technology studies. Information, Communication & Society, 0(0), 1–16. https://doi.org/10.1080/1369118X.2017.1410205
Moats, D., & Borra, E. (2018). Quali-quantitative methods beyond networks: Studying information diffusion on Twitter with the Modulation Sequencer. Big Data & Society, 5(1), 2053951718772137. https://doi.org/10.1177/2053951718772137
Procter, R., Vis, F., & Voss, A. (2013). Reading the riots on Twitter: methodological innovation for the analysis of big data. International Journal of Social Research Methodology, 16(3), 197–214. https://doi.org/10.1080/13645579.2013.774172
Puschmann, C. (2018). Spezialisierte Lexika. Retrieved November 27, 2018, from http://cbpuschmann.net/inhaltsanalyse-mit-r/4_lexika.html
Rogers, R. (2013). Digital Methods. Cambridge, Massachusetts London, England: MIT Press.
Rogers, R., & Marres, N. (2000). Landscaping climate change: a mapping technique for understanding science and technology debates on the world wide web. Public Understanding of Science, 9(2), 141-163.
Smyrnaios, N, S. Chauvet and E. Marty ( 2017) The Impact of CrossCheck on Journalists & the Audience, First Draft, 2017, https://firstdraftnews.org/wp-content/uploads/2017/11/Crosscheck_rapport_EN_1129.pdf
Steel, R. (1999) Walter Lippmann and the American Century, Transaction Publishers.